GLIWA T1 與 IAR:符合 ISO 26262 標準的量產級時序監控解決方案
GLIWA T1 是汽車產業中部署最廣泛的時序分析工具之一,已在數百個量產專案中使用多年。
作為全球首創,通過 ISO 26262 ASIL-D 認證的 T1-TARGET-SW,讓以儀表化(instrumentation)為基礎的時序分析與時序監控得以安全地應用在車內系統,而且是量產環境。
為什麼 IAR 工具鏈是 GLIWA T1 儀表化追蹤的最佳夥伴?
在眾多編譯器工具鏈中,GLIWA T1 支援 IAR 的 Arm Cortex-M 嵌入式開發工具(包含預先認證版本)。
實務上這是一個非常理想的組合,因為 IAR 工具鏈所提供的最佳化機制,正好完全符合 T1 的需求。
時序量測解決方案 T1 能讓你以直覺的方式掌握軟體的即時特性。
它是一套可攜式、純軟體的解決方案,透過對受測軟體進行儀表化來運作:當即時作業系統(RTOS)發生任務切換時,會呼叫 T1_TraceEvent(),並以時間戳記記錄該事件。
累積的大量事件追蹤資料可上傳至 PC 進行視覺化分析。此時,你就能清楚看見各種非預期行為,例如任務執行時間過長、過短,或甚至完全漏掉某些執行週期。
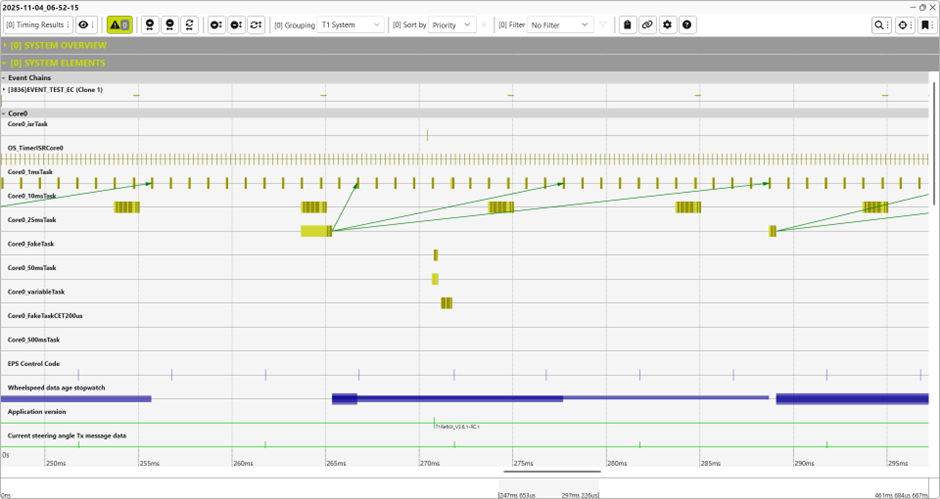
T1.scope 視覺化分析:在資源受限系統中實現高效能軟體追蹤
下圖展示了 T1 的 T1.scope 視覺化畫面,讓使用者能清楚理解系統內部的時間行為。
除了其他功能之外,T1 也針對所有關鍵時序指標(CET、GET、DT 等)提供 profiling,以有效支援系統分析。
以軟體為基礎的 tracing 並非 T1 所獨有。某種程度上,T1 可被視為一種 printf 除錯的變形,而 printf 除錯是最古老、也最原始的追蹤與除錯方式之一。
T1 真正獨特之處,在於它在資源受限的嵌入式系統中仍能保持高度效能。
軟體式 tracing 的根本問題在於:儀表化本身會改變我們想量測的系統。如果額外負擔(overhead)過高,系統將無法正常運作,也就無法取得任何有意義的時序資料。
因此,從這個角度來看,「只拿到T1 最少但必要的資訊」反而是理想狀態。
即使 overhead 非常低,只要它夠穩定,我們仍能嘗試辨識其影響;但若 overhead 變動幅度很大,就只能猜測實際上應用程式花了多少時間,以及有多少時間是被 T1 的儀表化所消耗。
技術詳解:利用 IAR 編譯器優化減少 T1 儀表化產生的分支指令與時序抖動
以下我們來看一個經過前處理(因此會看到不少「魔術數字」)的小型 C 程式碼範例,這個範例清楚展現了 T1 與 IAR 工具鏈(包含 IAR C/C++ 編譯器)之間的良好搭配。
這個函式會對被追蹤的事件進行前處理,將合併在一起的 eventInfo 值拆解為事件與資訊欄位,並為該事件選擇合適的事件處理器。那個大型的 if 條件,用來判斷事件是否屬於某一組特定值。
最直覺的寫法可能是一連串的 if-else,或是一個 switch。
這裡我們改用 bit mask,協助編譯器找出更有效率的實作方式,而實際上這種寫法在 IAR 上的效果非常好,後面會看到。
T1_tickUint_t T1_TraceEventNoSusp__( T1_scopeFgConsts_t *pScopeConsts, T1_eventInfo_t eventInfo ){ T1_uint8Least_t handlerIdx; T1_uint16Least_t eventId = ( eventInfo >> 10 ) & 0x3Fu; eventId = ( 15u < eventId ) ? 15u : eventId; handlerIdx = 0u; if( 0uL != ( ( ( ( 1uL << 12u ) | ( 1uL << 1u ) | ( 1uL << 3u ) | ( 1uL << 2u ) | ( 1uL << 14u ) | ( 1uL << 13u ) | ( 1uL << 4u ) | ( 1uL << 5u ) | ( 1uL << 6u ) | ( 1uL << 8u ) | ( 1uL << 7u ) ) >> eventId ) & 1uL ) ) { handlerIdx = eventId; eventInfo &= 0xFFFFFFFFuL >> ( 32 - 10 ); } return pScopeConsts->pDispatcher( pScopeConsts, eventInfo, handlerIdx << 1 );}
接著我們來看編譯器輸出的反組譯結果。
T1_TraceEventNoSusp__: 0x3f20: 0x0a8b LSRS R3, R1, #10 0x3f22: 0x2b0f CMP R3, #15 ; 0xf 0x3f24: 0xbf28 IT CS 0x3f26: 0x230f MOVCS R3, #15 ; 0xf 0x3f28: 0xf247 0x12fe MOVW R2, #29182 ; 0x71fe 0x3f2c: 0x40da LSRS R2, R2, R3 0x3f2e: 0xf012 0x0201 ANDS.W R2, R2, #1 0x3f32: 0xbf1c ITT NE 0x3f34: 0x005a LSLNE R2, R3, #1 0x3f36: 0xf3c1 0x0109 UBFXNE R1, R1, #0, #10 0x3f3a: 0x6a43 LDR R3, [R0, #0x24] 0x3f3c: 0x4718 BX R3 0x3f3e: 0xbf00 NOP
第一個值得注意的是,這段程式碼沒有建立stack frame。透過 pDispatcher 的函式呼叫被最佳化為 tail call,直接轉成一個 BX 指令。
再加上編譯器只使用了函式易變(function-volatile)暫存器,因此完全不需要 stack frame。對於這麼小的函式來說,配置與回收 stack frame 的額外負擔其實會相當可觀。
第二個重點是,程式碼中完全沒有條件分支指令。
原本的兩個條件(一個三元運算子 ?:,一個 if)都被編譯成 Thumb-2 的條件式指令,包在 IT block 中。
這種無分支(branchless)的程式碼,在具備管線化與 burst fetch 的現代 Arm 處理器上表現特別好。
不僅消除了 branch misprediction 的風險,也不會佔用有限的分支預測資源,讓呼叫端的程式碼也能有更好的效能。最重要的是,相較於有條件分支的寫法,時序會穩定得多。
事實證明,我們用 bit mask 來判斷集合成員的技巧確實發揮了效果。
既然編譯器做得這麼好,為什麼還要自己寫組語?
另一個值得注意的最佳化,是大量使用 16-bit 的 Thumb 指令來縮小程式碼尺寸。
雖然指令較短不一定代表執行速度較快,但程式碼變小後,instruction cache 的使用效率會更好。
此外,為了減少 cache line 的使用數量,T1 也利用了 IAR 工具鏈對程式碼對齊(alignment)的支援,這也解釋了為什麼程式碼結尾會看到一個 NOP。
這個 NOP 是用來補齊,確保下一個函式能以 8-byte 對齊。
即使不清楚實際的處理器快取架構,8-byte 對齊在程式碼大小/padding 與效能之間,仍是一個相當不錯的折衷。
總結來說,如果我們如此在意效能,你可能會問:為什麼不乾脆直接用組語來寫?
原因有好幾個,最主要還是整體的成本效益考量。
當 IAR C/C++ 編譯器已經能從可攜式的 C 程式碼產生如此高品質的目標碼時,就很難再合理化撰寫與維護不可攜組語程式碼所付出的成本。
結論:結合 GLIWA 與 IAR 強化汽車軟體專案的功能安全與效能
看看 GLIWA T1 與 IAR 如何強化您的下一個汽車專案,深入了解 GLIWA 的時序工具、IAR 對汽車嵌入式開發的支援方式,並實際體驗 IAR 功能安全解決方案的互動式展示。
本文標題是向 Jakob Engblom 的經典論文〈Getting the Least Out of Your C Compiler〉致敬。
前往體驗 ➤ IAR 功能安全解決方案的互動式展示
本文由IAR提供